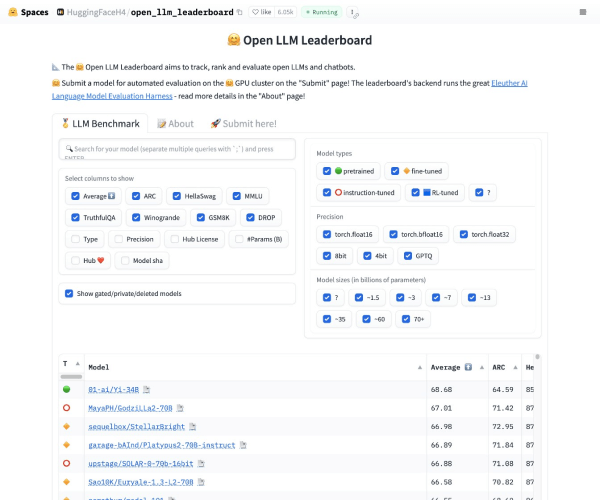
Open LLM Leaderboard |
Open LLM Leaderboard |
|
SuoLie-索猎免责声明与问题处理
1、本主题所有言论和图片,与本站立场无关 3、本主题由该帖子作者发表,该帖子作者与 {SuoLie-索猎} 享有帖子部分相关版权4、其他单位或个人使用、转载或引用本文时必须同时征得该帖子原作者和 {SuoLie-索猎} 的同意 5、帖子作者有恶意发布行为的,须承担一切因本文发表而直接或间接导致的民事或刑事法律责任 6、本帖部分内容转载自其它媒体,但并不代表本站赞同其观点和对其真实性负责 7、如本帖侵犯到任何版权问题,请立即告知本站,本站将及时予与删除并致以最深的歉意 8、本站-SuoLie-索猎提供的“本链接地址和内容”都来源于网络,不保证外部链接或者是本页与外页内容的准确性和完整性; 同时,对于该外部链接的指向,不由SuoLie-索猎实际控制; 在SuoLie-索猎收录时,该网页上的内容,都属于合规合法; 后期网页的内容如出现违规,可以直接联系网站管理员进行删除,SuoLie-索猎不承担任何责任。 9、 {SuoLie-索猎} 管理员和版主有权不事先通知发贴者而删除本文 SuoLie-索猎 最新常见问题解决方案: (出处: SuoLie-索猎) 本文由 明峻问道 发表于 2025-3-19 19:05,原文链接:https://1.suolie.com/thread-5748-1-1.html | |||||||||||||||||||||
相关帖子
|
|||||||||||||||||||||
 |
Archiver|
手机版|
小黑屋|
反馈举报|
侵权删除|
免责声明|
投诉建议|
联系我们|
赞助本站|
本站由cloudflare云安全提供防护加速服务|
索猎(SuoLie)
|
蒙ICP备2021002753号-6
|网站地图
|
Archiver|
手机版|
小黑屋|
反馈举报|
侵权删除|
免责声明|
投诉建议|
联系我们|
赞助本站|
本站由cloudflare云安全提供防护加速服务|
索猎(SuoLie)
|
蒙ICP备2021002753号-6
|网站地图
GMT+8, 2025-10-7 09:09 , Processed in 0.172544 second(s), 46 queries .
Powered by Discuz! X3.5
© 2001-2025 Discuz! Team.

 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



